
Key Takeaways
- 40%+ of agentic AI projects fail due to poor data foundations, not technology
- KYC/AML automation has the strongest production evidence base
- Mid-market teams need 4 pre-conditions before deploying any agentic workflow
- A 30/90/180-day roadmap is achievable for teams of 3–8 engineers
Introduction: The 40% Problem
Gartner predicts that over 40% of agentic AI projects will be canceled by end of 2027. That number gets cited in coverage that buries the lead. The real story is not that agentic AI is overhyped, it’s that most organizations are trying to deploy it before they’ve done the foundational work that makes it succeed. If you’re a VP of Data or a data architect at a mid-market financial services firm, you’ve probably felt this already: leadership wants an agentic AI roadmap, and you’re looking at your data stack wondering whether the pipes are actually ready for what they’re proposing.
This piece is written for you, not for whoever is sponsoring the initiative. It’s an honest account of where agentic workflows are working in financial services, what your data stack needs before you start, and how a team of five data engineers can build something real — without the resources of JPMorgan.
What are agentic workflows in financial services? Agentic workflows in financial services are automated processes in which AI agents independently plan, execute, and adapt multi-step tasks — such as KYC review, fraud detection, or compliance reporting — without requiring constant human direction. Unlike rule-based automation (RPA), agentic systems can reason over unstructured data, handle exceptions, and coordinate specialized sub-agents across a workflow. They are particularly well-suited to regulated environments because they generate complete, timestamped audit trails of every action taken — often more defensible than manual processes.
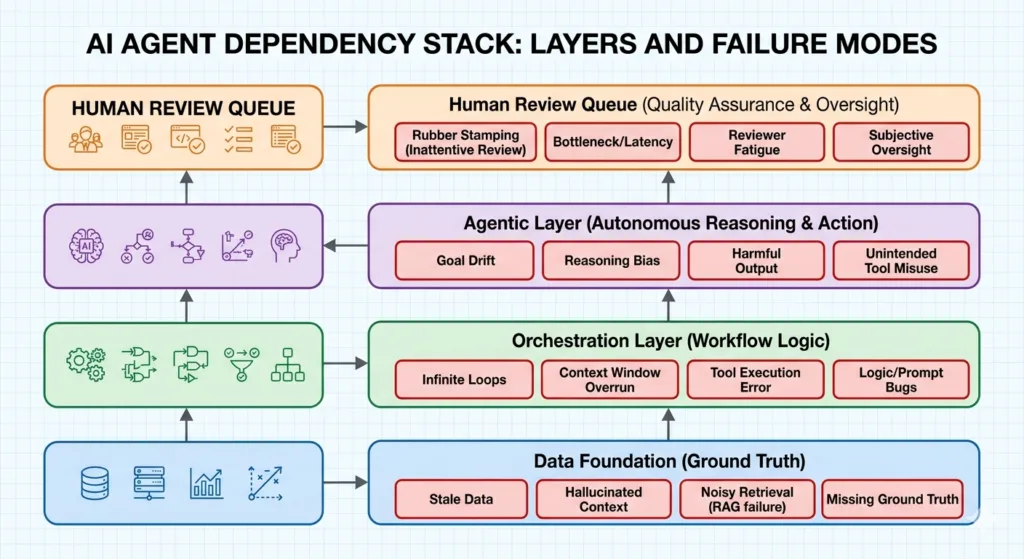
For data teams, the practical implication is this: agentic workflows do not replace your data pipeline. They run on top of it. Which means the quality of your data foundation determines whether agents produce reliable outputs or expensive failures.
What “Agentic” Actually Means for Data Teams
Strip away the vendor language and an agentic AI system looks familiar to anyone who has designed complex pipeline orchestration. You have an orchestrator that coordinates task execution, specialist components that perform discrete operations, shared state managed through intermediate outputs, and escalation logic for edge cases. The difference is that the components can reason, not just execute.
An Airflow DAG defines a fixed sequence of tasks. A dbt model transforms data according to explicit business logic. An agentic system reads the state of the environment, determines what action is appropriate, executes it, and checks whether the result is correct before proceeding. Agents don’t replace your orchestration tools — they sit above them and decide what the orchestration tools should do next. Your DAG still runs; now there’s an agent deciding whether its output is good enough to pass downstream.
Agentic AI vs. RPA: The Practical Difference for Financial Services
The RPA comparison comes up constantly, and conflating the two is a primary reason projects get scoped incorrectly. RPA is deterministic — it follows a script, operates on structured inputs in known locations, and breaks when the format changes. That’s appropriate for high-volume, stable processes like payment reconciliation. It has no ability to handle exceptions, reason over ambiguous inputs, or route edge cases.
Agentic AI is probabilistic and context-aware. Consider a credit application workflow: an RPA bot can move a completed application from an inbox to a processing queue. An agent can read the application, assess whether documentation is complete, identify missing fields, flag the appropriate underwriter based on risk profile, and route accordingly — without a predefined decision tree. When an exception occurs, the agent escalates to a human review queue with a structured summary of what it found and why. That exception handling is what makes agents applicable to the messy reality of financial services data.
Where Agentic Workflows Are Already Working in Financial Services
This is not an emerging technology waiting for production readiness. McKinsey, Deloitte, Oracle, and PwC have all published documented evidence of production deployments with measurable outcomes. Neurons Lab has cited PwC research reporting 25% cost savings in targeted financial services deployments. These are production systems running against real data in regulated environments, not proofs-of-concept.
The four use cases with the strongest evidence base for data teams are KYC/AML workflow automation, loan processing and credit risk decisioning, compliance reporting pipelines, and pipeline reliability and data quality monitoring. Each shares a common characteristic: high-volume, repetitive processes with clear inputs and outputs, significant variation in edge cases, and a meaningful cost to handling exceptions manually.
KYC and AML: The Highest-Credibility Use Case
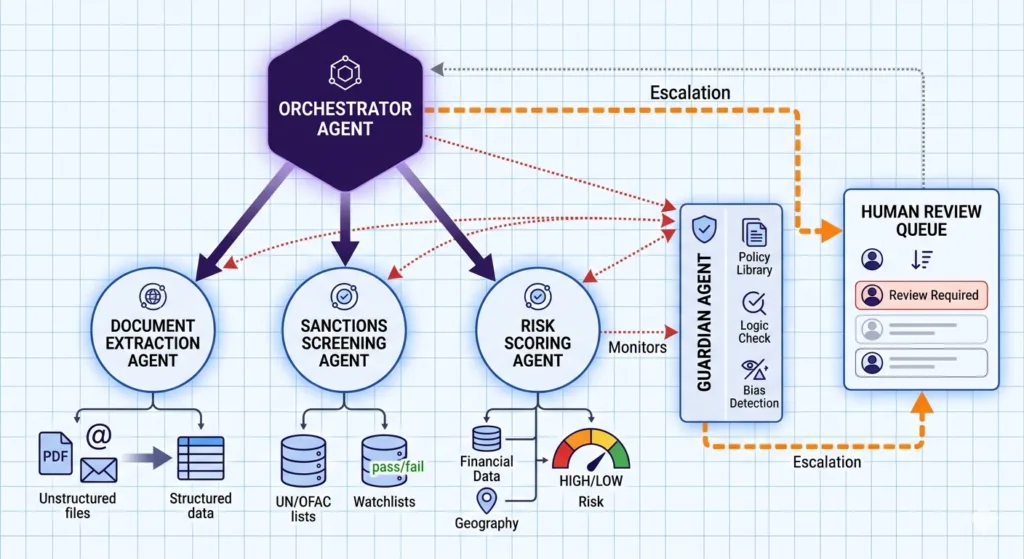
KYC and AML have the most documented production history of any agentic AI use case in financial services. Deloitte has published a multi-agent KYC review workflow in which an orchestrator agent coordinates three specialist sub-agents: one for document extraction and validation, one for sanctions screening, and one for risk scoring with supporting rationale. The orchestrator makes the routing call — clear approvals proceed, edge cases go to a human analyst with the agent’s structured finding attached.
McKinsey has documented a 20–60% productivity improvement in credit risk memo preparation and a 30% improvement in credit turnaround time at a US bank using agentic approaches to KYC and credit review. The wide productivity range reflects how sensitive outcomes are to data quality. The governance case is equally strong: every agent action is logged with a timestamp and rationale. When a regulator asks why a customer was flagged, the answer is a structured audit trail, not a reconstructed conversation.
Loan Processing and Credit Decisioning
Economist Impact and Oracle have documented a loan turnaround improvement from 48 days to 38 days at a financial services institution that deployed agentic workflow automation in its credit review process. A 10-day reduction sounds modest until you model it against application volume and the cost of capital in the processing queue.
Beam Data’s work on automated loan screening for mid-market fintech clients follows the same pattern: an ML-powered scoring layer on a governed data foundation, with agent coordination handling routing logic across the underwriting workflow. The agent doesn’t make credit decisions autonomously. It structures and routes inputs that human underwriters evaluate, with complete data lineage attached. The pre-condition is consistent across every case: clean, structured loan data with documented schema. Without it, the agentic layer produces outputs that look confident and are wrong.
Compliance Reporting and Audit Trail Automation
Data teams own the pipelines that feed compliance reports. Agentic layers can monitor those pipelines continuously, detect anomalies before they propagate into reports, generate draft compliance documentation with full lineage attached, and route exceptions to human review. The analyst’s job shifts from assembling the report to reviewing a structured draft and signing off.
This is the use case that tends to convert skeptical CTOs. Framed as risk mitigation — reducing the probability of a compliance reporting error that creates regulatory exposure — rather than automation efficiency, it maps directly to the financial services risk management calculus. Agent-generated audit trails are often more complete and more consistent than those produced by manual processes.
Pipeline Reliability and Data Quality Monitoring
This is the use case data teams own outright — no stakeholder coordination required, no credit decisioning risk, no external approvals. Agentic systems can monitor data pipelines continuously, detect schema drift and anomalous row counts before downstream consumers are affected, classify failure types by root cause, and route incidents to the appropriate on-call engineer with a structured diagnostic summary.
The pattern IBM has documented as a “guardian agent” architecture applies directly here: a supervisor agent monitors worker pipeline outputs, detects anomalies, and either corrects them automatically within defined tolerances or escalates with a structured problem report. For a data team managing a complex multi-source pipeline environment, this is often the highest-value first deployment — it reduces mean time to detection, reduces alert fatigue from undifferentiated monitoring noise, and generates the kind of data quality metadata that every downstream use case depends on. The data foundation requirement is the same. Agents monitoring data quality need consistent schemas and defined quality rules to detect deviations. If those rules don’t exist, the agent has no baseline to compare against.
What Your Data Stack Needs Before You Start
This is where most published content on agentic AI fails the practitioner. Deloitte and McKinsey write for the executive sponsor, not the data team responsible for building the system. The 40% cancellation rate Gartner projects is not a product quality problem — it’s a readiness problem.
Nicolas Bustamante, who has documented his experience building AI agents for financial services production environments, puts it plainly: even a well-scoped task like a DCF valuation requires multiple sequential agent steps, each depending on the previous step’s output being correct. One corrupted input propagates into every downstream decision. In financial services data environments, that’s not an edge case.
There are four pre-conditions that separate teams who will produce working agentic systems from those who will be in the 40%:
1. Clean, governed data foundation— schemas documented, lineage traceable, data quality rules defined and enforced
2. Defined workflows with explicit human-in-the-loop checkpoints — know where human judgment is required before you design the agent handoffs
3. Audit trail infrastructure — the ability to log every agent action with a timestamp and rationale, queryable by regulators and internal teams
4. Agent authorization governance framework — documented scope for each agent: what it can read, what it can write, what it can trigger, and what it cannot do
The Data Foundation Requirement
Agents reason over what they can read. If your schemas are inconsistent across source systems, your documentation is absent or outdated, or your data quality rules exist in tribal knowledge rather than enforced constraints, agents will produce outputs that look authoritative and are wrong. This is more dangerous than a broken ETL job, because a broken ETL job fails visibly. An agent with bad input data produces outputs that appear well-reasoned and are factually wrong.
A practical readiness test: can your team document the lineage of the five most business-critical data assets in your stack — where they come from, how they’re transformed, what quality checks they pass, and who owns them? If the answer is no for any of those five assets, the data foundation work comes before the agentic work. That’s not a delay — it’s the correct sequencing.
Beam Data’s work on real-time data infrastructure for fintech clients consistently shows the same pattern: the investment in data infrastructure — clean schemas, documented lineage, quality monitoring — is what enables the ML and AI layer to produce reliable outputs. Skipping that investment doesn’t save time. It relocates the failure to a less visible and more expensive stage.
Human-in-the-Loop Design Is Not Optional in Regulated Environments
The term “autonomous AI” creates a false impression that’s particularly dangerous in financial services. Agents are not autonomous in the sense of operating without accountability. They’re autonomous in the sense of executing without requiring a human to initiate each step. That distinction matters for governance design.
Every agentic workflow in a regulated environment needs defined escalation triggers from the start: conditions under which the agent stops, routes to a human review queue, and waits. What triggers escalation varies by use case — a confidence score below threshold, a data quality flag, an exception the agent wasn’t designed to handle — but the escalation mechanism is non-negotiable. AWS’s financial services implementation guidance describes this as constrained autonomy: it’s the correct design pattern for regulated industries, not a limitation to work around.
Technology Stack Compatibility
Data teams at mid-market firms don’t get to rebuild their stack to accommodate agentic AI. Snowflake, Databricks, dbt, Airflow, Prefect — whatever the stack is, it stays in place. Agentic layers integrate with those systems; they don’t require replacing them.
Matillion’s work on agentic data engineering integration makes this explicit: agents call existing pipeline components, read from existing data stores, and write outputs back into the same ecosystem. The agent layer is a routing and decision layer above the existing infrastructure, not a parallel stack. Beam Data works across AWS, Azure, GCP, and hybrid environments, and the integration pattern holds regardless of which cloud the underlying stack runs on.
How to Build Agentic Workflows: Architecture for Mid-Market Data Teams
The architecture that works for a team of 3–8 data engineers is not a simplified version of what JPMorgan deploys — it’s a different design philosophy. Fewer specialized agents, more explicit handoffs, human checkpoints at higher frequency, and a deliberately narrow scope. A tier-1 bank builds a platform. A mid-market data team builds a workflow.
The core pattern: an orchestrator agent coordinates task sequencing and routing; specialist agents execute discrete tasks within defined scope; a human escalation layer receives structured summaries when defined triggers fire. IBM has documented a “guardian agent” pattern for self-healing pipeline architecture: a supervisor agent monitors worker agent outputs, detects anomalies, and either corrects them automatically or escalates to a human with a structured problem report. This pattern works well for small teams because the guardian agent handles quality assurance centrally rather than requiring domain expertise built into every individual agent.
Start with One Workflow, Not a Platform
The worst pattern in agentic AI deployment is buying a platform before building a workflow. Vendor platforms promise to handle the hard parts — agent coordination, state management, tool integration — and they can, but only if you know what workflow you’re building and what success looks like. Teams that buy first and define later end up with expensive infrastructure and undefined criteria for success.
Start with one workflow: clear boundaries, measurable outcome, an existing data foundation that already supports it. Build the simplest version that runs in production, measure it against the process it replaces, prove it works, then expand. For most mid-market financial services data teams, the best first workflow is compliance reporting pipeline monitoring. It has lower-stakes than credit decisioning, faster to prove value, and a pain point the data team already owns.
The Multi-Agent Architecture Pattern
Beam Data applied this structure in building an automated forecasting pipeline for a marketplace client — orchestrator manages sequence and state, specialist components execute with defined inputs and outputs, handoffs are explicit. The same design principle applies to financial services. Each agent needs documented scope. The documneted scope: what it reads, what it writes, what it can trigger downstream, and what conditions cause it to escalate. The pattern holds on AWS Bedrock, Azure AI Studio, or an open-source stack — the infrastructure choice is secondary to getting the scope definition right.
Governance and Compliance Requirements for Agent Systems
A well-designed architecture is deployable in a regulated environment only when governance requirements are built into it from the start — not added after the first audit finding. Governance for agentic AI is not a compliance checkbox. It’s the design work that makes the system work in production, and it should happen before the first line of code.
Explainability for Every Agent Decision
Every agent decision must be explainable — a human reviewer must be able to trace the inputs that produced a specific output and understand the routing logic. This is not a theoretical requirement. When a credit applicant is flagged, when a compliance exception is escalated, when a data quality alert fires, the record of what the agent read and what it concluded must be retrievable on demand. Design the logging first; build the agent logic after.
Immutable and Queryable Audit Logs
Audit logs must be immutable and queryable: every agent action logged with timestamp and rationale, retrievable by regulators on request. This is both a technical requirement and a data governance requirement. Agent-generated logs are a distinct data type with their own retention and access controls. If your current governance framework doesn’t treat them that way, that’s a gap to close before deployment — not after.
Documented and Enforced Agent Authorization Scope
Each agent’s authorization scope must be documented and enforced. The document extraction agent cannot initiate a credit approval. The compliance monitoring agent cannot modify source data. Scope constraints are a security requirement and a governance requirement simultaneously. AWS’s guidance on agentic AI in financial services makes this explicit, though the principles are technology-agnostic. They derive from GDPR and the broader financial services regulatory framework. GDPR makes no exemption for AI-generated decisions: an agent processing customer data is subject to the same data handling requirements as a human performing the same task.
Frequently Asked Questions
1. What is the difference between agentic AI and RPA?
RPA is deterministic — it follows a predefined script and breaks when the format changes. Agentic AI is context-aware. It reads the current state of the environment, reasons about the appropriate action, and adapts when exceptions occur. In financial services, RPA can move a completed application from an inbox to a processing queue. An agent can read the application, assess whether documentation is complete, flag missing fields, and route to the appropriate underwriter based on risk profile — without a predefined decision tree.
2. What is the most important pre-condition for deploying agentic workflows?
A clean, governed data foundation. Agents reason over what they can read. If your schemas are inconsistent, documentation is absent, or data quality rules aren’t enforced, agents will produce outputs that appear well-reasoned and are factually wrong. Before building any agentic workflow, your team should be able to document the lineage of your five most business-critical data assets: where they come from, how they’re transformed, what quality checks they pass, and who owns them.
3.How long does it take to build a production agentic workflow?
For a mid-market financial services team of 3–8 engineers, expect roughly 6 months from data foundation audit to first production deployment. The first 30 days go to auditing data readiness and identifying the highest-value candidate workflow. The next 60 days go to a sandbox build with parallel testing. The final period covers production deployment with human-in-the-loop checkpoints, audit trail verification, and baseline metrics established before go-live.
4.What happens if our data foundation isn’t ready?
Skipping the data foundation step doesn’t defer the cost — it relocates it. Agents deployed on undocumented, inconsistent data produce confident-looking outputs that create downstream errors and, in regulated environments, potential compliance exposure. The data foundation work comes before the agentic work. That’s the correct sequencing for every production deployment that’s working in financial services today.
5. Should we buy an agentic AI platform or build the workflow ourselves?
Build the workflow first. Vendor platforms can handle agent coordination and state management. But only when you have a defined workflow with measurable success criteria. Teams that buy a platform before building a workflow end up with expensive infrastructure and undefined criteria for success. Start with one workflow in a sandbox environment — if a platform genuinely accelerates that, adopt it at that point.
What a Realistic Starting Point Looks Like
The 30/90/180-day roadmap below is calibrated for a mid-market financial services data team of 3–8 engineers. This is without a dedicated ML platform team. It’s designed to produce a production-running agentic workflow within six months while managing risk at each stage.
30 days — Data Foundation Audit:
– Document the five most business-critical data assets in your stack (lineage, schema, quality rules, ownership)
– Identify the highest-value candidate workflow for agentic automation — use the criteria above (clear boundaries, existing data foundation, measurable baseline)
– Assess your current pipeline observability. Can you detect data quality failures in real time, or do you find out from downstream consumers?
90 days — Sandbox Build:
– Build one agentic workflow in a sandbox environment against real, de-identified data
– Run it in parallel with the existing manual or automated process for 30 days
– Compare outputs systematically. Where does the agent match the existing process, where does it deviate, and are the deviations improvements or errors?
6 Months — Production Deployment:
– Move to production with human-in-the-loop checkpoints implemented and tested
– Audit trail in place and verified against regulatory requirements
– Defined success metric established before go-live, with a review scheduled at 90 days post-deployment
If you’re not sure whether your data foundation is ready to support this roadmap, the fastest way to find out is a free AI strategy consultation with Beam Data’s team. We’ll assess your current stack against the pre-conditions above and give you an honest answer about sequencing. One session, no commitment Schedule here.
The Practical Path Forward
The 40% cancellation rate Gartner projects is not inevitable. It’s the outcome of skipping foundational work — deploying agents on unvalidated data, without defined escalation checkpoints, without documented agent scope, without a clear success metric. Every production deployment that’s working in financial services today built the data foundation first.
Agentic AI is not a technology you adopt. It’s a capability you build on top of infrastructure you’ve already governed. If the foundation is ready, deployment is manageable. If it’s not, no vendor platform changes that outcome.
The data teams that will have working agentic workflows in production twelve months from now are not the ones with the largest AI budgets. They are the ones who did the unglamorous infrastructure work first — and that work is entirely within a data team’s control, independent of executive sponsorship, vendor selection, or AI budget.
If you want an outside perspective on where your stack stands, schedule a free AI strategy consultation with Beam Data. We work with mid-market financial services teams specifically. And we’ll tell you what we actually see — not what you want to hear.
